A few months ago I was exploring the write-ups and video solutions for the retired HackTheBox machine – Quick. It’s during this exploration that I came across HTTP/3. For those that are not aware, HTTP/3 is the upcoming third major version of the Hypertext Transfer Protocol used to exchange information on the World Wide Web, succeeding HTTP/2.
Now, to be honest, my knowledge of the Hypertext Transfer Protocol (HTTP) has mainly been restricted to the HTTP/1.0 and HTTP/1.1 specifications. In particular, as that is the main specifications of the protocol we (security pentesters) observe in Burp (our intercepting proxy) when assessing web applications. We are familiar and comfortable seeing HTTP GET/POST requests and the myriad of responses that can be received (e.g., 400, 503…)
When I started deep-diving into the HTTP/2 and HTTP/3 specifications, I realised just how many websites and platforms have transitioned to (at least) HTTP/2. Hence, my interest was piqued into understanding what the differences are between the old and new specifications, and whether they hold any new assessment opportunities or security vulnerabilities – put simply, are there new risks we need to explore?
Naturally, before I could quantify the new opportunities, I had to first understand the critical differences between the specifications and the underlying technology they use. This involved looking at the HTTP/2 and HTTP/3 specifications respectively and seeing how they were presented differently in the existing pentest toolset (i.e. Burp) and modern web browsers. It also made sense to spin up local web servers and web applications to see these specifications in action.
In this blog post, we will first explore the key differences between the HTTP/1.x, HTTP/2 and HTTP/3 specifications. This will involve mainly a theoretical overview. With the theoretical understanding in place, we will transition to using these specifications to interact with Internet-based web servers and web applications. The key focus will be on how the specifications differ at the OSI network and application layers. Finally, we’ll explore how the existing pentest toolset can be changed to cater to the differences.
A Quick Look at the Evolution of the HTTP Protocol
Before we dive into HTTP/2 and HTTP/3, let’s have a quick look at the evolution of the HTTP protocol over the years to better understand why HTTP/2 and HTTP/3 were introduced.
The HTTP (stateless) protocol was developed by Tim Berners-Lee and his team between 1989-1991. HTTP was and continues to be an application protocol for distributed, collaborative, hypermedia information systems. HTTP is the foundation for data communication for the World Wide Web, where hypertext documents include hyperlinks to other resources that the user can easily access, for example by a mouse click or by tapping the screen.
HTTP/1.0
In 1996, the HTTP/1.0 specification was published which defined the raw HTTP textual wire format as we know it today (for the purposes of this post we’ll ignore HTTP/0.9 which technically was published a few years earlier). In HTTP/1.0 a new TCP connection is created for each request/response exchange between a client and server, meaning that all requests incur a latency penalty as the TCP and TLS handshakes are completed before each request:
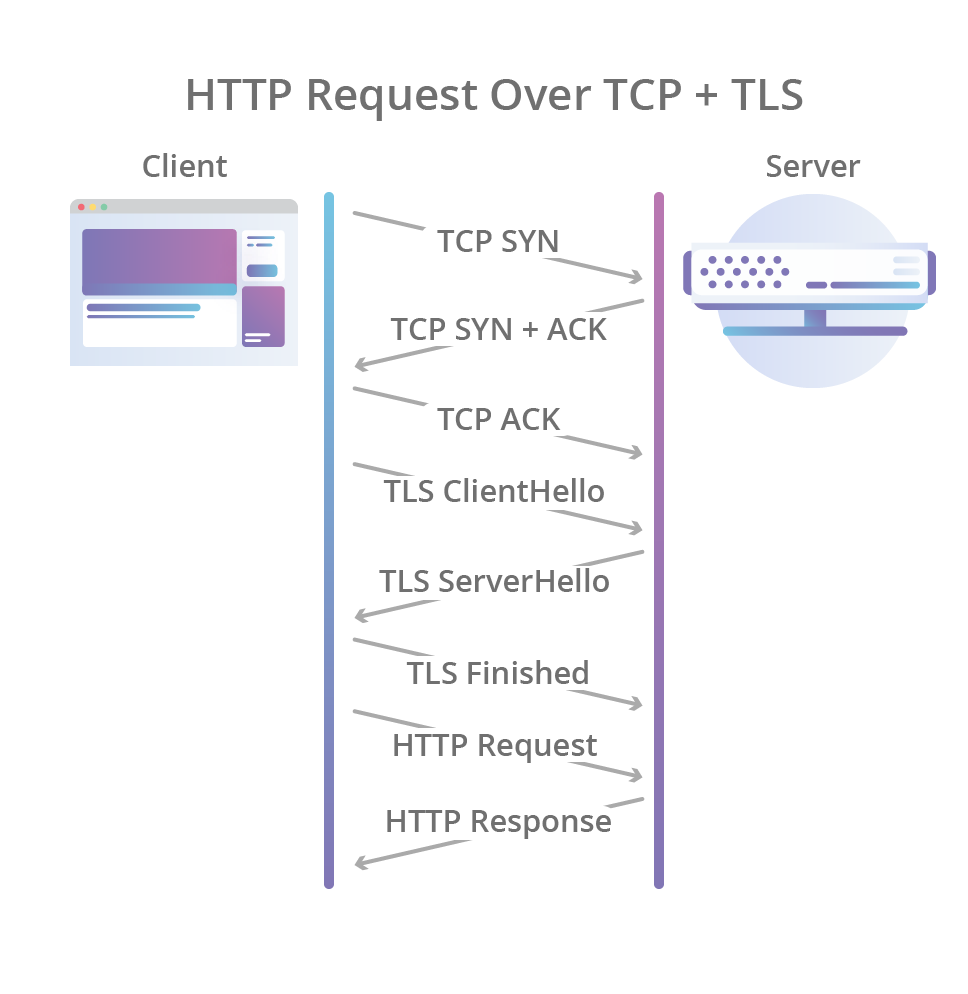
The specification also incurs other latency issues, including what is now known as a “slow start”. TCP enforces a warm-up period called “slow start”, which allows the TCP congestion control algorithm to determine the amount of data that can be in flight at any given moment before congestion on the network path occurs. This process introduces a short period of latency and reduces the maximum network bandwidth that can be used at the start of the TCP connection.
HTTP/1.1
The HTTP/1.1 revision of the HTTP specification tried to solve these problems a few years later by introducing the concept of “keep-alive” connections – I am sure we’ve all seen this item in the HTTP headers when viewing HTTP requests. What the “keep-alive” concept does is it allows clients (i.e. browsers) to reuse TCP connections, and thus amortize the slow start penalty over multiple requests.
In principle, the “keep-alive” concept worked great. A single TCP connection is established between the server and client and remains connected while HTTP requests/responses are exchanged sequentially.
To improve concurrency, a mechanism had to be found whereby multiple HTTP requests/responses could be issued at the same time across the single TCP connection. The initial idea was to simply have the client establish more connections to the web server, but this required multiple TCP connections to the same origin in parallel. In doing so, the benefits of “keep-alive” connections would be lost as you would now have 10+ connections to the same source anyway. Hence, an alternative had to be found.
HTTP/2
HTTP/2, among other things, introduced the concept of HTTP “streams”. “Streams” is a feature that allows HTTP implementations to concurrently multiplex different HTTP requests/responses over the same TCP connection, allowing browsers to more efficiently reuse TCP connections:
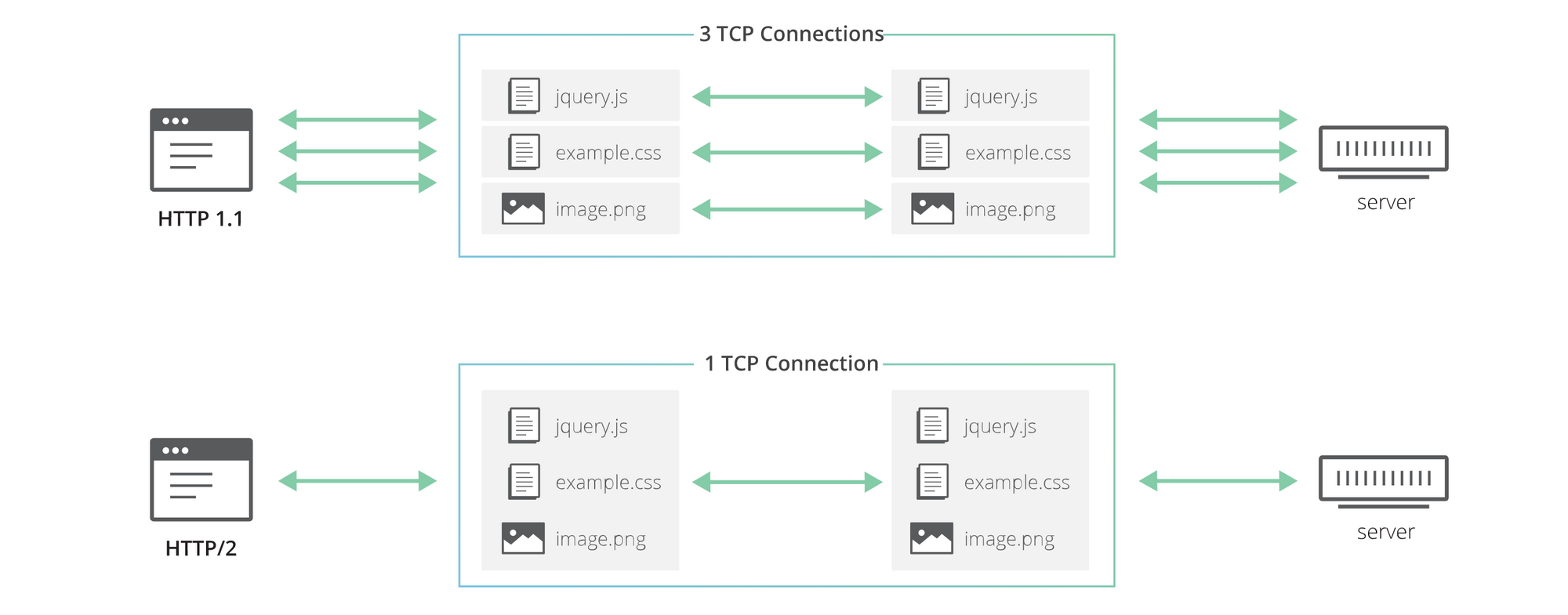
In theory, HTTP/2 was the silver bullet solution the Internet required. Multiple HTTP exchanges could occur over the same TCP connection. Hence, latency was reduced (supposedly), and concurrency was at a maximum. Unfortunately, the underlying technology itself was the problem; namely TCP.
The role of TCP is to deliver an entire stream of bytes, in the correct order, from one endpoint to the another. When a TCP packet carrying some bytes is lost on the network path, it creates a gap in the stream and TCP needs to fill it in by resending the affected packet. While doing so, none of the successfully delivered bytes that followed the lost one can be delivered to the web browser, even if they were not themselves lost and belonged to a completely independent HTTP request. So they end up getting unnecessarily delayed as TCP cannot know whether the web browser would be able to process them without the missing bits.
HTTP/3
The proposed HTTP/3 specification replaces the underlying TCP protocol for a new alternative known as QUIC – originally named “Quick UDP Internet Connections”. QUIC packets are encapsulated on top of UDP datagrams. Hence, QUIC doesn’t suffer from the latency and packet loss problem observed in HTTP/2.
The same logic of HTTP/1.x and HTTP/2 still applies, it is the transportation of the exchange that is different. In particular, with QUIC, HTTP requests/requests are embedded into UDP datagrams. The net result looks something akin to the following:
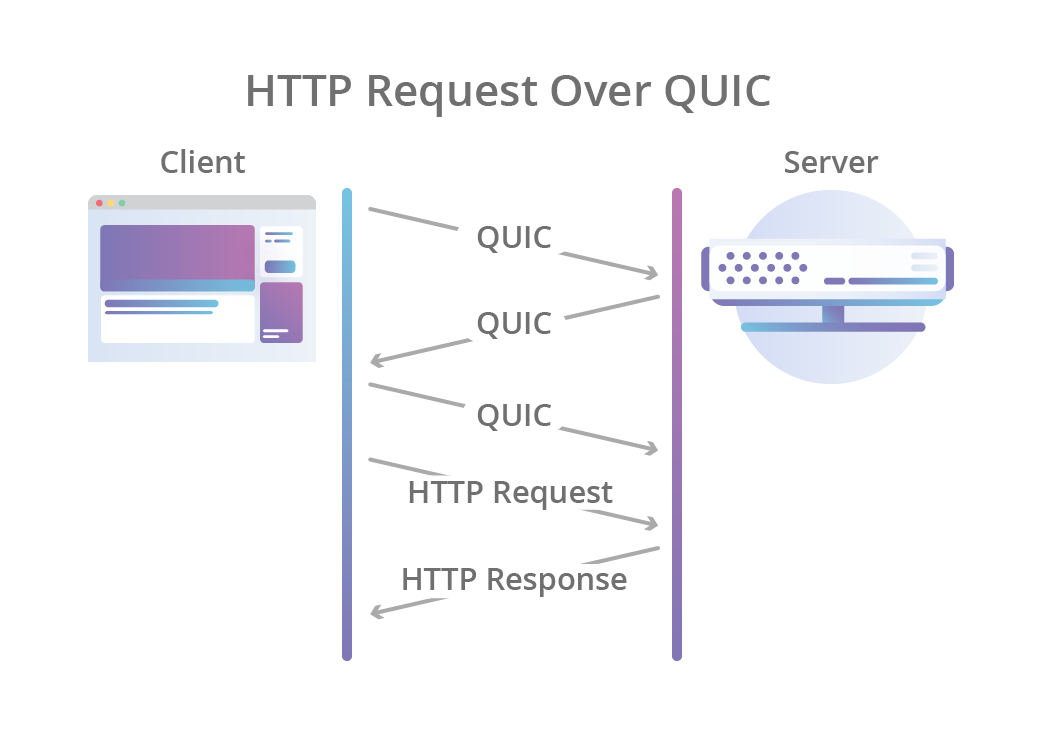
Seen in the figure above, the HTTP exchange starts with a few QUIC UDP datagrams being exchanged between the client and the server. Once the UDP datagrams are unpacked, the embedded HTTP request/responses are processed. The only difference is this happens a thousand times a second for all the JavaScript, images and other resources that load for a website.
Seeing HTTP/1.x and HTTP/2 in Action: In the Browser, Burp and WireShark
The keen reader would argue at this stage saying HTTP/2 and HTTP/3 still operate on the exact same principle. You have an HTTP request sent from the client to the server, and the server responds with an HTTP response. Whether that is done over TCP or UDP, a single connection or multiple; the traffic is still delivered. This is entirely true when considering the application layer of the OSI model alone. If you consider the changes at the network layer; then things are quite different. So let’s explore both layers by navigating to different sites within our browser and inspecting the traffic with Burp and WireShark.
HTTP/1.x
We start with the most basic of tests. We navigate to a site that only supports HTTP/1.x:
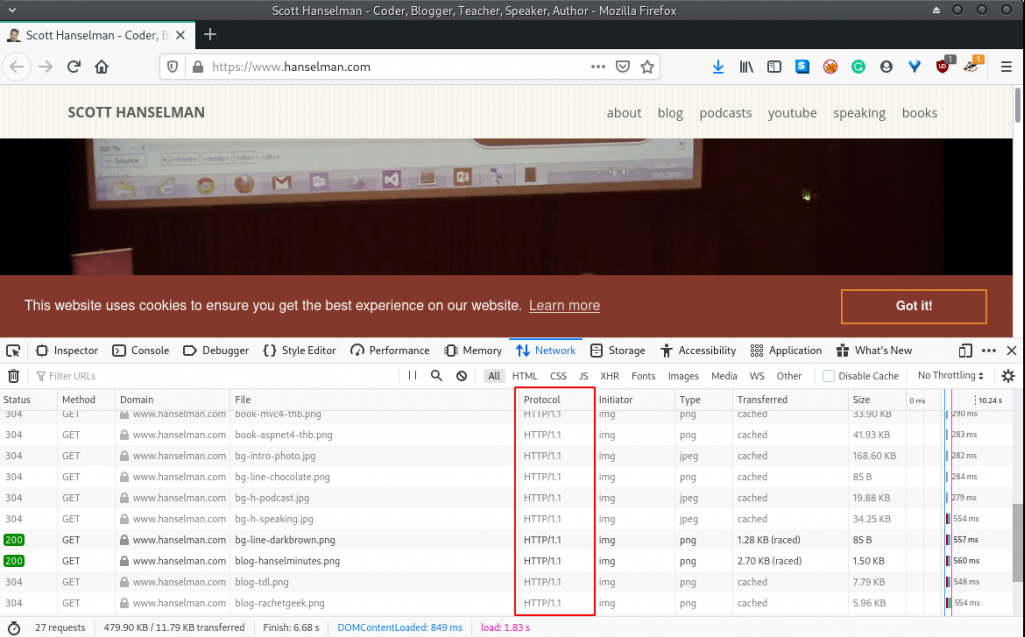
Using the Firefox Development Tools and navigating to the Network tab; we notice that the HTTP/1.1 specification was used for the HTTP exchange between the browser and the web server.
Naturally, we could confirm the same by looking at the Burp logs. Notice how the HTTP/1.1 specification is specified on line 1 in the HTTP request:
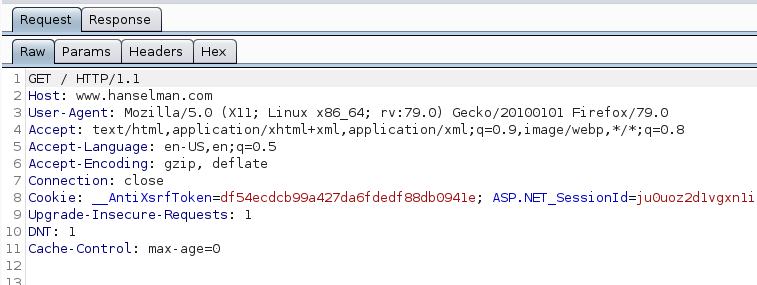
If we recall back to the earlier section, the HTTP/1.1 specification uses multiple TCP connections but allows them to remain open to be reused when the “keep-alive” option is specified. For the demonstration above I deliberately chose a site that doesn’t make use of it. The result is that when we inspect the network traffic with WireShark, we notice multiple TCP connections were made between the browser and web server:
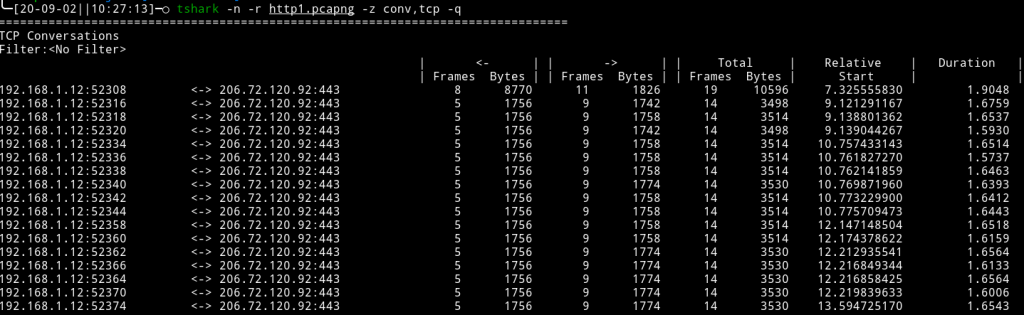
HTTP/2
We’ve confirmed in the previous test that HTTP/1.x is quite inefficient and raises multiple TCP connections. How do the results change when we browse to an HTTP/2-capable site? Luckily, we can test this easily since most modern sites already have the support – more on this later.
For demonstration purposes, we’ll navigate to the SensePost website in our browser while the Firefox Developer Tools is running. Here is what we observe:
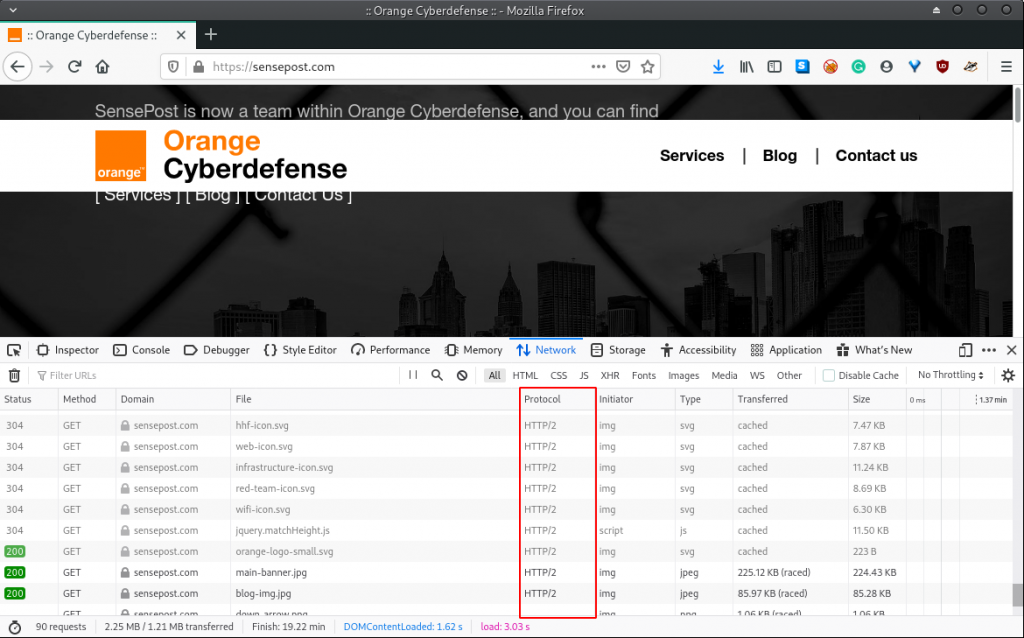
We notice that the HTTP/2 specification was automatically used for the HTTP exchange between the browser and web server. Obviously, we would want to confirm that we see the same in Burp. However, this is where things become a little strange.
In Burp, the requests are made using HTTP/1.x:
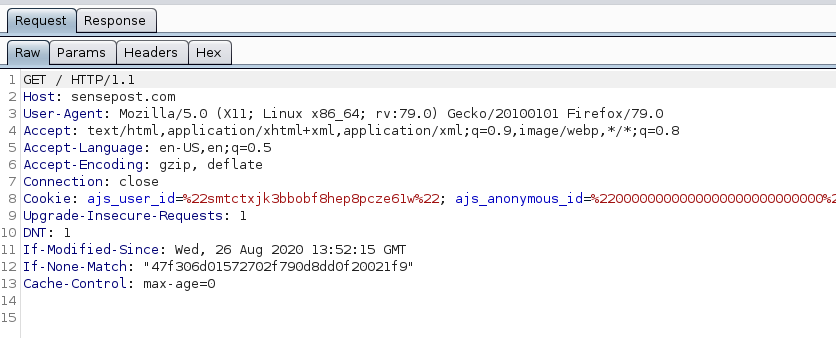
Why would it be different? The reason is Burp acts as its own ‘browser’ of sorts. Burp is by default using the HTTP/1.x specification and the website is able to automatically downgrade – backward compatibility exists between HTTP/1.x and HTTP/2. The result is that you’ll only ever see the HTTP/1.x specification being used by Burp… that is, until recently.
With the release of Burp v2020.6, PortSwigger introduced a feature whereby the HTTP/2 specification can be used. It is located under the Project options -> HTTP tab:

When enabled, the HTTP/2 specification is used by Burp to handle HTTP requests/responses. For example, if we enable the option and revisit the SensePost website we get a slightly different HTTP request:
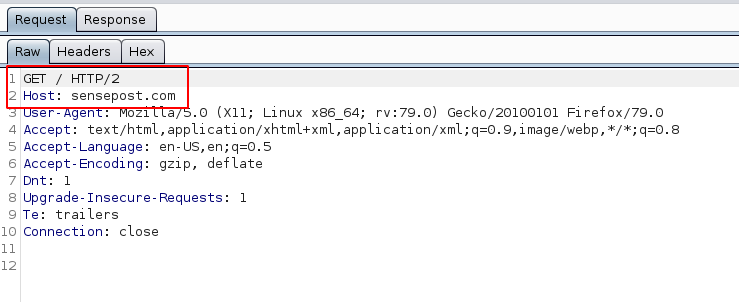
The interesting part is what Burp is doing behind the scenes. The HTTP/2 specification is actually a binary protocol (see below). Hence, you can’t edit the contained data in the same manner that you would HTTP/1.x traffic.
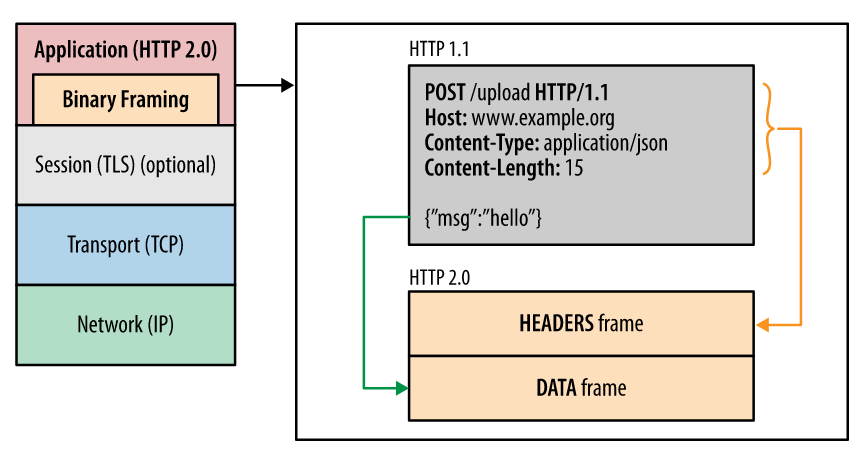
What PortSwigger designed is a translation/transposition layer whereby the binary protocol is converted to the HTTP/1.x specification. This allows us (pentesters) to view the HTTP requests/responses in Burp as usual. Just know that the traffic being sent to/from the web server is vastly different.
The above results account for what the browser and Burp are seeing during an HTTP/2 exchange. The WireShark results are also quite revealing around what is actually happening at the network layer:
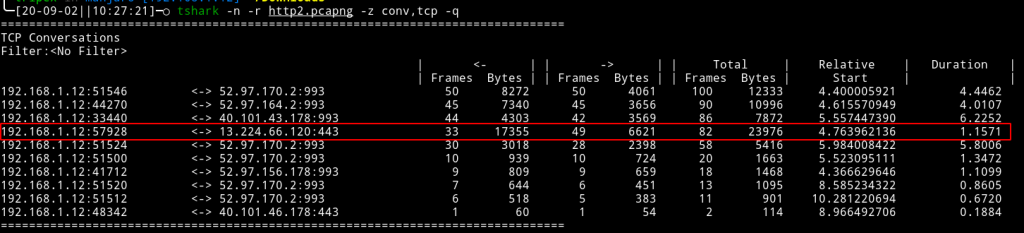
[Note: I had other web sites open in the browser, so the results are a bit exaggerated here.]
Exactly as the HTTP/2 specification states, the SensePost site was loaded using a single TCP connection. Within this connection, all the images, JavaScript and other resources necessary to load the website were downloaded:

[Note: A time and speed difference may not be immediately apparent between the HTTP/1.x and HTTP/2 specifications. If a website has few resources that are being downloaded, the difference between the two specifications may be marginal.]
Technically there was a myriad of other things that happened during the exchange with the website. The HTTP/2 specification allows for things like request and response multiplexing, flow control, stream prioritisation, header compression and many other concepts. These concepts won’t immediately be visible from a browser perspective, but they are present at the network layer. For those keen to explore these concepts in more detail; please refer to https://developers.google.com/web/fundamentals/performance/http2/
Sidebar: How to Setup an HTTP/2 Compatible Web Server
Before moving on to HTTP/3, it might be useful to understand how a developer or system administrator would set up an HTTP/2 compatible web server. The setup process depends entirely on whether a CDN is used or not, and what web server technology is being employed.
If a CDN is being used like Cloudflare, Incapsula, MaxCDN or Amazon CloudFront, the developer or system administrator may not need to enable HTTP/2 on their web server(s) as it can rather be enabled at the CDN network edge. In such cases, the CDN will automatically upgrade and downgrade communication between what it receives and what the web server supports. This is akin to how Burp’s HTTP/2 support currently operates (except that instead of doing it client-side, the logic moves server-side). A translation or transposition takes place at the CDN network edge.
If a CDN is not utilised, then HTTP/2 support has to be enabled on the web server itself. The first requirement is that the web server has to be configured with HTTPS – since browsers currently support the HTTP/2 specification over HTTPS only.
The exact steps required to enable HTTP/2 support are different between Apache, Nginx and other web server technologies. For example, to configure it on Apache and Nginx works as follows:
- HTTP/2 can be deployed in Apache HTTP 2.4.17 or later version with the help of the mod_http2 module.
- Nginx 1.9.5 or higher version support HTTP/2. Enabling HTTP/2 in Nginx is just a matter of adding an http2 parameter to the listen directive:
server {
listen 443 http2 ssl ...;
…....
}Exploring the HTTP/3 Specification
The previous section explored the HTTP/1.x and HTTP/2 specifications while they were used by a browser to reach a public web server. The important takeaway is that both specifications made use of TCP connections. Furthermore, they were already known and implemented by modern browsers. When moving to HTTP/3, the concepts mostly turn theoretical since the specification has not yet seen wide adoption.
HTTP/3 Support in Web Browsers and Servers
HTTP/3 support was introduced in modern browsers towards late 2019 and early-to-mid 2020:
| Browser | Version implemented (disabled by default) | Date of release |
|---|---|---|
| Chrome | Stable build (79) | December 2019 |
| Firefox | Stable build (72.0.1) | January 2020 |
| Safari | Safari Technology Preview 104 | April 2020 |
| Edge | Edge (Canary build) | 2020 |
In Firefox 88.0 (which I am using currently), HTTP/3 support is enabled by default. You can confirm the status of HTTP/3 support using the about:config page:
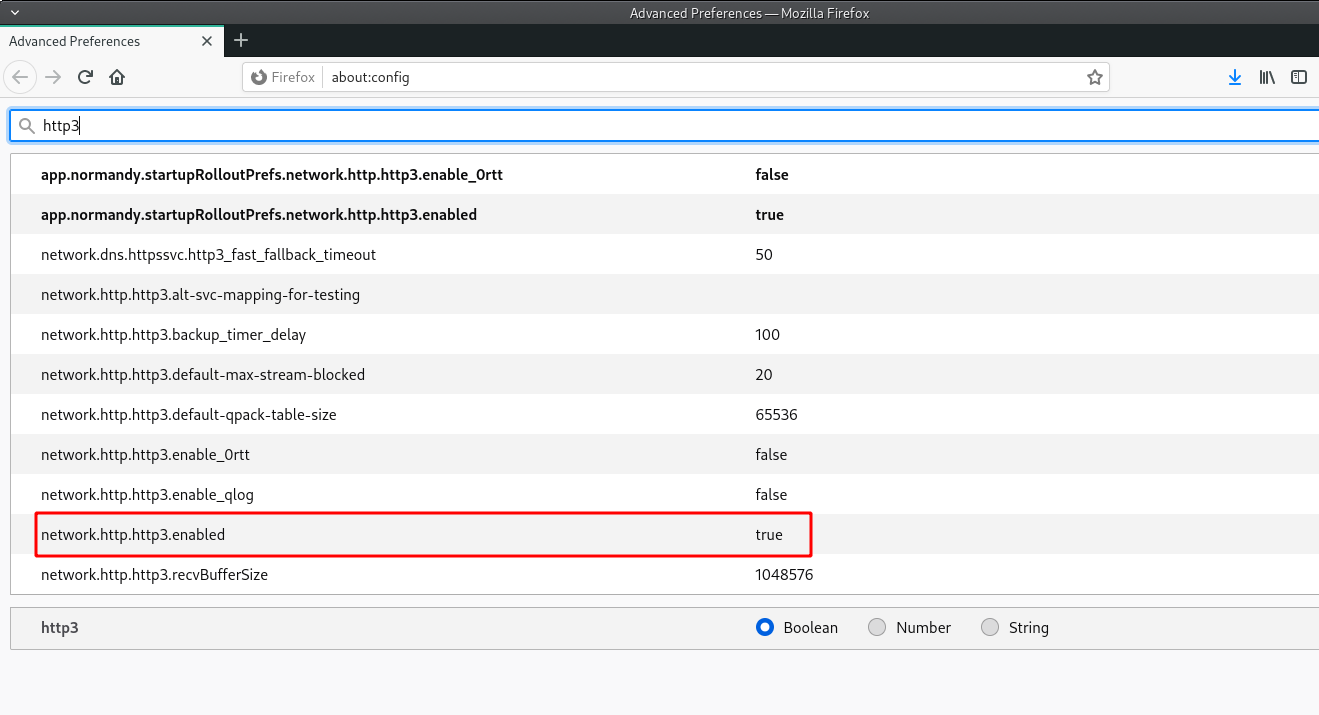
To use the Chrome browser (i.e. 90.0) to connect to a website over HTTP/3, you can enable QUIC support using the chrome://flags page:

In the search box on the Experiments page, type “QUIC” in the search box and to filter out all experimental features and quickly find the “Experimental QUIC protocol” flag.

Click on the “Default” drop-down menu box next to “Experimental QUIC protocol” flag, and select “Enabled” from the available options.

Naturally, the above settings only affect the browser and would not automatically upgrade the public web servers users are browsing to. There are a few public web services that have already been upgraded, including elements of Google’s services and Facebook.
Cloudflare is also one of the first CDNs that started to automatically introduce HTTP/3 support for their clients. Their implementation is open-source and written in Rust, including both a server component and CLI client. It has been published under the name of Quiche:
https://github.com/cloudflare/quiche
For clients making use of their CDN network, enabling HTTP/3 support is as easy as swapping a toggle on the CDN distribution’s control panel:

Seeing the HTTP/3 Specification in Action with Firefox
For demonstration purposes, I’ll use Firefox for this section. To follow along I’ve already confirmed the HTTP/3 support is enabled using the about:config page:
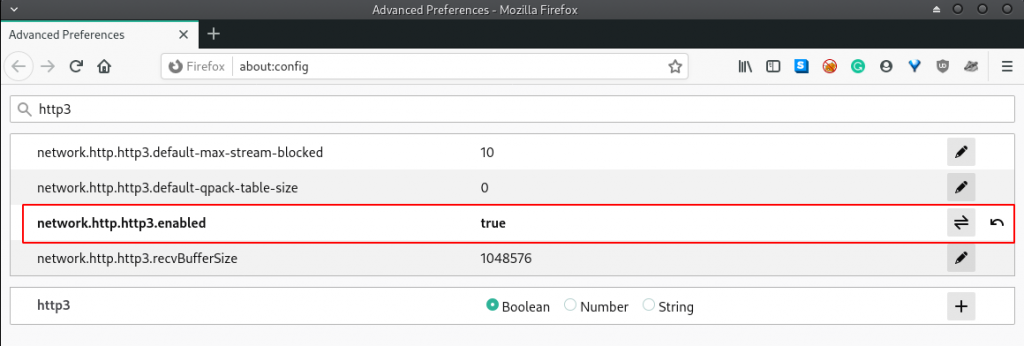
CloudFlare created a live HTTP/3 web server that can be reached at:
https://quic.tech:8443/Let us use Firefox and browser to this site in our browser while the Firefox Developer Tools is running. Here is what we observe:

We notice that the HTTP/3 specification was automatically used for the HTTP exchange between the browser and web server. On initial inspection this doesn’t appear to be much different to what we noticed with HTTP/2; however let us not forget that UDP datagrams were used to reach this site.
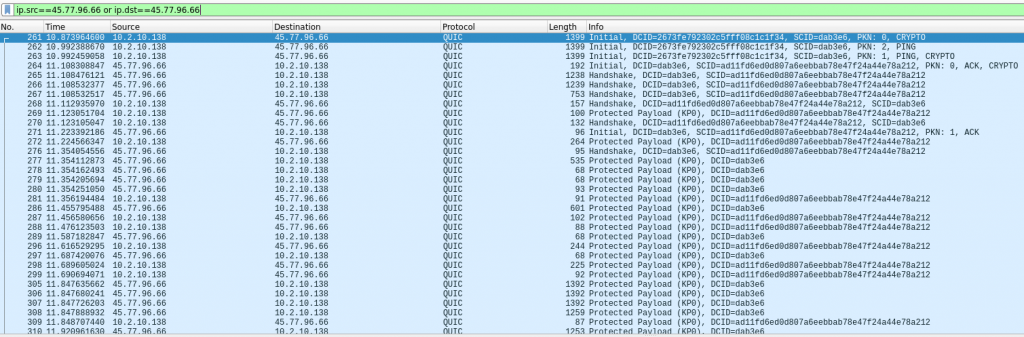
If we capture the network traffic between the browser and the site using WireShark, the results are quite revealing around what is actually happening at the network layer:

The entire HTTP exchange with the site was done using UDP datagrams. We can also see this graphically using the WireShark GUI:
An interesting fact when viewing the UDP datagrams is that TLS encryption is handled directly in the datagrams themselves (the first few packets handle the cryptographic exchange). Unlike HTTP/1.x and HTTP/2 where HTTPS/TLS is bolted in separately during the HTTP exchange; QUIC allows it to be applied natively. In fact, QUIC fails soonest if the TLS connection cannot be established – for example, a valid SSL certificate has to be offered by the web server.
[Note: It should be noted that you might still observe HTTP/2 traffic even when browsing HTTP/3 capable sites. The reason for this is that services like Google and Facebook interact with many 3rd party sites that have not yet been upgraded.]
Security Implications of the HTTP/3 Specification
To understand the security implications of the HTTP/3 specification; it is useful to consider what ports a web developer or system administrator would need to open on the web server.
Let’s consider the following Dockerfile for an HTTP/3 compatible Nginx web server:
version: '3.1'
services:
nginx:
image: nwtgck/nginx-http3
ports:
- '80:80'
- '443:443'
- '443:443/udp'
depends_on:
- ghost
restart: always
volumes:
- ./nginx.conf:/usr/local/nginx/conf/nginx.conf
# NOTE: Should set cert properly
- /etc/letsencrypt/live/nwtgck-nginx-http3.tk/fullchain.pem:/etc/ssl/certs/server.crt
# NOTE: Should set key properly
- /etc/letsencrypt/live/nwtgck-nginx-http3.tk/privkey.pem:/etc/ssl/private/server.key
ghost:
image: ghost
restart: always
expose:
- "2368"Apart from the obvious TCP/80 and TCP/443 ports being exposed; notice how the developer is required to expose UDP/443. It is exactly this that could raise an interesting security implication.
Most firewall appliances have been configured to specifically allow and filter TCP connections to web servers. It is debatable whether provision has been made for UDP connections. Web application firewalls (WAFs) would also experience difficulties. Most WAFs contain rules to inspect and block attacks in TCP packets. Would the same logic automatically apply to UDP datagrams? Perhaps time will tell, once HTTP/3 is more widely adopted.
The key takeaway from this section should be that UDP port scans will become increasingly important for external security posture checks. We have already seen the implications of the IKE service (UDP/500) in the past. Likely UDP/443 will experience similar troubles as system administrators unknowingly open restricted web servers to the Internet.
Conclusion
In this blog post, we explored the key differences between the HTTP/1.x, HTTP/2 and HTTP/3 specifications. This involved mainly a theoretical overview. With the theoretical understanding in place, we transitioned to using these specifications to interact with Internet-based web servers and web applications. We also explored how the specifications differ at the OSI network and application layers. Finally, we explored how our existing toolset can be changed to cater to the differences.
As noted in the blog post, the HTTP/2 specification does hold some security implications but they are mainly at the OSI network layer. Since the HTTP/2 specification is a binary protocol; it naturally opens up the attack surface for buffer overflow, DoS and stuffing vulnerabilities. These vulnerabilities and flaws in HTTP/2 have seen some major news coverage over the past few years. For example, Imperva did a study and published their results:
https://www.imperva.com/docs/Imperva_HII_HTTP2.pdf
The HTTP/3 specification and QUIC is still early in its development and likely will see much change as their adoption becomes more widespread. QUIC’s use of UDP datagrams certainly brings many benefits and concurrency improvements, but it also introduces some ‘potentially’ unintended firewall issues. As stated in this blog, we’ll have to see whether these issues truly materialise over time. However, having awareness of them at this stage is perhaps a good initial step.
References
- https://en.wikipedia.org/wiki/HTTP/2
- https://developers.google.com/web/fundamentals/performance/http2/
- https://gizmodo.com/what-is-http-2-1686537168
- https://forum.portswigger.net/thread/http2-support-2f8c093c606a895130c886
- https://httpd.apache.org/docs/2.4/howto/http2.html
- https://geekflare.com/http2-implementation-apache-nginx/
- https://en.wikipedia.org/wiki/HTTP/3
- https://http3.net/
- https://quicwg.org/base-drafts/draft-ietf-quic-http.html
- https://blog.cloudflare.com/http3-the-past-present-and-future/
- https://blog.cloudflare.com/enjoy-a-slice-of-quic-and-rust/
- https://github.com/cloudflare/quiche
- https://github.com/nwtgck/ghost-nginx-http3-docker-compose
- https://www.howtogeek.com/442047/how-http3-and-quic-will-speed-up-your-web-browsing/
- https://us-cert.cisa.gov/ncas/current-activity/2019/08/14/multiple-http2-implementation-vulnerabilities
- https://www.zdnet.com/article/severe-vulnerabilities-discovered-in-http2-protocol/
- https://www.imperva.com/docs/Imperva_HII_HTTP2.pdf